Support Engineering
How Resilinc cut MTTR by 62% with Decimal
Faster resolution, fewer escalations, and a more autonomous Support organization

Sanjeet Hajarnis

Highlights
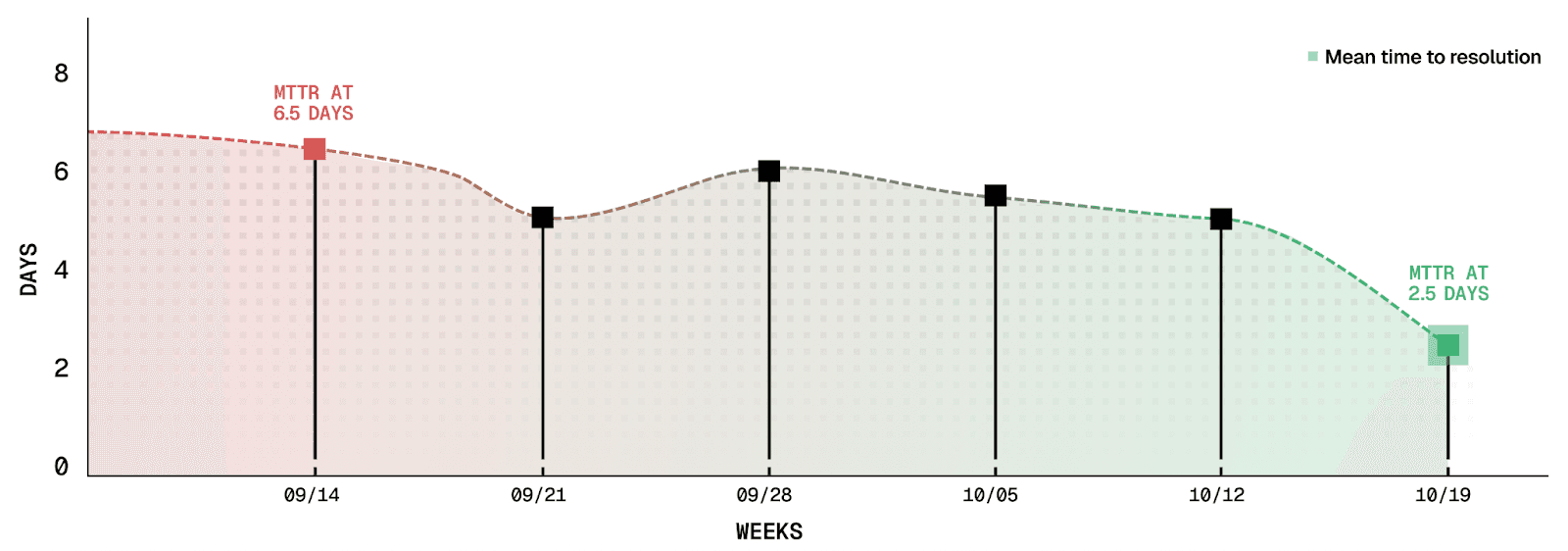
Mean time to resolution dropped from 6.5 days to 2.5 days
The knowledge base updates went from monthly updates to minutes after ticket closure
Zero workflow changes with Decimal directly integrated into Freshdesk
Better-vetted escalations with issues validated by Decimal before reaching Product or Engineering
Company
Resilinc is the leading platform for supply chain risk monitoring, mapping, and predictive disruption intelligence. Global manufacturers, healthcare systems, and high-tech OEMs rely on Resilinc to anticipate disruptions, understand supplier dependencies, and maintain operational continuity at scale.
Resilinc's Agentic AI Factory is an expanding portfolio of intelligent agents, each purpose-built for a specific supply chain risk, compliance, or operational domain. These agents sense, recommend, and take action, guided by configurable policies and human oversight. The Agentic AI Factory is modular, extensible, and designed to enable autonomous, self-healing supply chains, setting it apart from general-purpose AI platforms by delivering domain-specific intelligence and automated workflows.
Challenges
Resilinc’s Support organization manages a wide spectrum of deeply technical issues: API and integration behavior, configuration troubleshooting, data investigations, and repeated or ambiguous product bugs. Even with strong documentation processes and mature internal practices, many tickets required engineering-level investigation to understand expected versus actual system behavior.
The result was a familiar pattern:
Slower ticket resolution
Heavy dependence on engineering
Repeated questions
Knowledge gaps when features are released
It created meaningful delays for customers and stretched the engineering team into work they shouldn’t have needed to do.
“Decimal gives us the clarity we used to rely on Engineering for. The team now feels confident using Decimal’s answers directly with customers.”
Manoj Khaire, Manager of Customer Support Engineering
Solutions
Resilinc deployed Decimal’s AI Support Engineer across their full ticket volume, integrating directly into Freshdesk to enhance existing workflows and drive more efficient troubleshooting and continuous knowledge improvement.
From the moment a ticket is created, Decimal analyzes the reported behavior using its understanding of Resilinc’s product to generate detailed private notes that include root cause analysis, explanation of product behaviour, potential workarounds and next steps.
Decimal’s AI Support Engineer remains active throughout the entire lifecycle of a ticket. As new information arrives, logs, screenshots, new customer replies, it reevaluates the case and posts follow-up clarifications automatically.
After a ticket is closed, Decimal drafts a knowledge article by analyzing the entire ticket, prioritizing new information that wasn’t previously captured. This creates a self-updating knowledge base that grows with every resolved issue and subsequently accelerates future ticket resolution.
Decimal also helped streamline Resilinc’s internal workflows by identifying tickets that should bypass Support entirely and flow directly to Data Operations. Roughly 25% of Resilinc’s support volume fell into this category, yet these tickets previously required manual triage and handling before reaching the right team. By classifying Data Ops related tasks early, Decimal reduced unnecessary Support intervention and eliminated avoidable handoffs. This automated routing accelerated resolution for customers and allowed Support to stay focused on true investigative and customer-facing work.
Beyond end to end ticket resolution, Resilinc’s team finds immense value out of Playground that gives Customer Success, Product, and other teams the ability to access engineering-level answers on demand, supporting deeper technical understanding without relying on Engineering.
Three critical capabilities stood out to the team:
Engineering level internal notes
Automatic knowledge generation
On-demand engineering insights through Playground
These improvements quickly changed how the team operated. Support began resolving issues confidently with far more context, and escalations were better-vetted because Support could validate expected behavior directly against the code instead of asking Product or Engineering.
“Decimal has become a core part of how we operate. It speeds up today’s workflow and gives us a foundation to scale support more efficiently going forward.”
Mike Flewwelling, Vice President of Customer Success and Support
Results
Faster resolution, fewer escalations, and a more autonomous Support organization
Decimal delivered measurable impact in under four weeks.
Mean Time to Resolution dropped from 6.5 days to 2.5 days - As part of Resilinc’s broader AI-driven transformation of Support, spanning from migrating to Freshdesk, improving internal processing around ticket management and better knowledge management practices, Decimal acted as a force multiplier that unlocked faster ticket resolution. Support gained the ability to diagnose system behavior immediately, reducing the historical reliance on engineering for validation. This combination of foundational improvements and AI acceleration drove MTTR down from 6.5 days to 2.5 days.
Knowledge base updates went from monthly to minutes after ticket closure - articles that once required weeks of manual writing and review are now generated automatically, providing Support and CSMs with fresh, accurate answers almost instantly.
Zero workflow changes with Decimal integrated directly into Freshdesk - The team continued using their existing processes, tags, and triage flows. Decimal simply is another support engineer inside their workflow contributing on all tickets from day one.
More efficient collaboration between Support, Product and Engineering - Better-vetted issues, faster ticket progress, and automated knowledge generation reduced the manual effort required across teams.
“Decimal didn’t add a new workflow. It became part of our existing one. The lift was minimal, and the impact was immediate”
Ravi Suryanarayan, Senior Vice President of Agent Success and Operations
Looking ahead
Decimal - a strategic part of Resilinc’s support operations
With Support fully up and running on Decimal, adoption has expanded to Customer Success. Product is next, aiming to leverage Decimal’s insights to understand recurring issues and knowledge gaps across releases.
Resilinc now views Decimal as a strategic, agentic-first capability that strengthens Support’s autonomy and accelerates technical problem solving across the organization.
“Decimal has accelerated how we serve some of the biggest organizations in the world. It strengthens support autonomy today and it fits directly into how our company is evolving - agent first”
Kamal Ahluwalia, CEO







